Spark: What Problems an Adaptive Query Execution (AQE) Solved?
Problem: Inadequate use of the resouces
Some of the major issues with Spark data processing stem from inadequate resource utilisation, such as a single node processing data while multiple nodes wait for it to finish.
The main reasons for this issue are due to:
1. Data skew
Data skew occurs when the data to be processed is unevenly distributed. (For example, sales on Black Friday will be much higher than on any typical day, causing a data skew when processing data by date on Black Friday).
2. Uneven input data:
This occurs when the data to be processed is uneven in size. For example, if your data consists of multiple smaller files, having extremely small or large files can cause the reading nodes to be inefficiently used.
3. Spark not exploiting intermediate data statistics:
When processing data, Spark learns its characteristics. However, not changing the processing plan based on new information means Spark is not utilising the data statistics to its full potential.
Solution: Adaptive Query Execution (AQE)
With the help of Adaptive Query Execution (AQE), Spark handles the above issues automatically.
With Spark 3.0, the new feature called Adaptive Query Execution (AQE) enables Spark to modify the query plan based on the statistics of the partially processed intermediate data.
AQE works as follows:
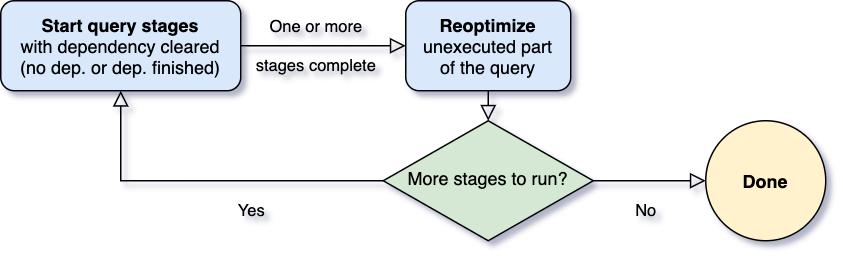
-
1.) Spark completes the stages that have no dependency
-
2.) Based on the output of the stage, the plan is re-optimised
-
3.) If there are no more stages to run, STOP else go to step 1
Thanks to AQE, the optimisation process that used to take data engineers a long time has been mostly automated.
Adaptive Query Execution in Spark dynamically optimises query execution plans based on runtime statistics.
During query processing, Spark generates multiple intermediate physical plans before arriving at a final, optimal plan for execution.
The presence of isFinalPlan=false suggests that the optimiser is still evaluating different strategies, making adjustments based on data characteristics, and hasn't settled on the final version of the plan to execute.
In practical terms, it allows Spark to make runtime decisions to improve performance, such as:
-
Adjusting join strategies based on the actual size of data.
-
Re-optimising shuffle partitions for better load balancing.
-
Combining adjacent stages was beneficial.
isFinalPlan=false means that the plan is still in an intermediate stage, and AQE may continue refining it to produce a more efficient final plan for the query.
# Spark SQL REPL session
USE tpch;
EXPLAIN EXTENDED
SELECT
o.orderkey,
SUM(l.extendedprice*(1-l.discount)) AS total_price_wo_tax
FROM
lineitem l
JOIN orders o ON l.orderkey=o.orderkey
GROUP BY
o.orderkeySee the Spark plan below (search for "isFinalPlan")
== Parsed Logical Plan ==
'Aggregate ['o.orderkey], ['o.orderkey, 'SUM(('l.extendedprice * (1 - 'l.discount))) AS total_price_wo_tax#6]
+- 'Join Inner, ('l.orderkey = 'o.orderkey)
:- 'SubqueryAlias l
: +- 'UnresolvedRelation [lineitem], [], false
+- 'SubqueryAlias o
+- 'UnresolvedRelation [orders], [], false
== analysed Logical Plan ==
orderkey: bigint, total_price_wo_tax: double
Aggregate [orderkey#28L], [orderkey#28L, sum((extendedprice#17 * (cast(1 as double) - discount#18))) AS total_price_wo_tax#6]
+- Join Inner, (orderkey#12L = orderkey#28L)
:- SubqueryAlias l
: +- SubqueryAlias spark_catalog.tpch.lineitem
: +- HiveTableRelation [`tpch`.`lineitem`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#12L, partkey#13L, suppkey#14L, linenumber#15L, quantity#16, extendedprice#17, discount#..., Partition Cols: []]
+- SubqueryAlias o
+- SubqueryAlias spark_catalog.tpch.orders
+- HiveTableRelation [`tpch`.`orders`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#28L, custkey#29L, orderstatus#30, totalprice#31, orderdate#32, orderpriority#33, clerk#..., Partition Cols: []]
== optimised Logical Plan ==
Aggregate [orderkey#28L], [orderkey#28L, sum((extendedprice#17 * (1.0 - discount#18))) AS total_price_wo_tax#6]
+- Project [extendedprice#17, discount#18, orderkey#28L]
+- Join Inner, (orderkey#12L = orderkey#28L)
:- Project [orderkey#12L, extendedprice#17, discount#18]
: +- Filter isnotnull(orderkey#12L)
: +- HiveTableRelation [`tpch`.`lineitem`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#12L, partkey#13L, suppkey#14L, linenumber#15L, quantity#16, extendedprice#17, discount#..., Partition Cols: []]
+- Project [orderkey#28L]
+- Filter isnotnull(orderkey#28L)
+- HiveTableRelation [`tpch`.`orders`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#28L, custkey#29L, orderstatus#30, totalprice#31, orderdate#32, orderpriority#33, clerk#..., Partition Cols: []]
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[orderkey#28L], functions=[sum((extendedprice#17 * (1.0 - discount#18)))], output=[orderkey#28L, total_price_wo_tax#6])
+- HashAggregate(keys=[orderkey#28L], functions=[partial_sum((extendedprice#17 * (1.0 - discount#18)))], output=[orderkey#28L, sum#39])
+- Project [extendedprice#17, discount#18, orderkey#28L]
+- SortMergeJoin [orderkey#12L], [orderkey#28L], Inner
:- Sort [orderkey#12L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(orderkey#12L, 200), ENSURE_REQUIREMENTS, [plan_id=43]
: +- Filter isnotnull(orderkey#12L)
: +- Scan hive tpch.lineitem [orderkey#12L, extendedprice#17, discount#18], HiveTableRelation [`tpch`.`lineitem`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#12L, partkey#13L, suppkey#14L, linenumber#15L, quantity#16, extendedprice#17, discount#..., Partition Cols: []]
+- Sort [orderkey#28L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(orderkey#28L, 200), ENSURE_REQUIREMENTS, [plan_id=44]
+- Filter isnotnull(orderkey#28L)
+- Scan hive tpch.orders [orderkey#28L], HiveTableRelation [`tpch`.`orders`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [orderkey#28L, custkey#29L, orderstatus#30, totalprice#31, orderdate#32, orderpriority#33, clerk#..., Partition Cols: []]
Time taken: 0.457 seconds, Fetched 1 row(s)In the above query plans, you can see in AdaptiveSparkPlan, it has
isFinalPlan=false, indicating that AQE is turned on and the plan may change during execution.
The presence of
isFinalPlan=falseindicates that the current query plan is not yet finalised and is still subject to further optimisation by AQE.
Note: The above image taken from Databricks blog
Post Tags: